Btrfs
Updated 7 Avril 2021
![]()
Introduction
Btrfs est un système de fichiers destiné à répondre aux exigences croissantes d'évolutivité des grands sous-systèmes de stockage. Son nom fait référence aux structures de données B-tree, qu'utilise Btrfs. L'arbre B est une structure de données arborescente qui permet aux systèmes de fichiers et aux bases de données d'accéder efficacement à de grands blocs de données et de les mettre à jour, quelle que soit la taille de la structure.
Au moment du partitionnement, vous pouvez sélectionner Btrfs comme système de fichiers lors de l'installation de Calculer Linux. Le programme d'installation formatera alors en conséquence la partition que vous aurez sélectionnée. En outre, vous pouvez utiliser `mkfs.btrfs' pour créer un système de fichiers Btrfs sur un ou plusieurs périphériques blocs. Par défaut, les données sont partitionnées et les métadonnées du système de fichiers sont mises en miroir. Lorsque vous spécifiez un ordinateur distinct, les métadonnées y sont copiées, à moins que vous n'ayez spécifiquement indiqué qu'une seule copie des métadonnées doit être utilisée. Les périphériques peuvent être de simples partitions disque, des périphériques de bouclage (c'est-à-dire des images disque stockées en mémoire), des périphériques à chemins multiples ou des périphériques LUN qui mettent en œuvre le RAID au niveau matériel.
Fonctionnalités
Ci-dessous les caractéristiques principales de Btrfs :
- Copy-on-write permet de créer des instantanés lisibles et modifiables, indispensables pour restaurer votre système de fichiers, même après une conversion ext3 ou ext4. Utilisez la commande suivante pour créer un instantané :
btrfs subvolume snapshot <source> <[dest/]name>Pour empêcher les modifications, ajoutez la clé -r. - La somme de contrôle garantit l'intégrité des données.
- La compression intégrée permet d'économiser de l'espace disque. La compression peut être activée par l'option compress=zlib ou compress=lzo lors du montage du volume de stockage. La compression peut également être activée pour les fichiers individuellement sans utiliser l'option de montage : pour ce faire, appliquez
chattr +c <[dest/]name>au fichier. Lorsque cette option est appliquée à un répertoire, les nouveaux fichiers seront automatiquement compressés suivant leur soumission. - La défragmentation intégrée améliore la productivité.
- La gestion intégrée des volumes logiques permet de mettre en œuvre des configurations RAID, ainsi que l'ajout et la suppression dynamiques de supports de stockage.
Btrfs prend en charge les systèmes RAID0, RAID1, RAID10, RAID5 et RAID6. Il peut également dupliquer des métadonnées ou des données ordinaires sur un ou plusieurs disques.
Attention
RAID5 et RAID6 sont connus pour leurs problèmes d'intégrité des données et ne doivent pas être utilisés pour le stockage des métadonnées. Le problème, c'est qu'une écriture fragmentée - causée, par exemple, par une coupure d'électricité pourrait entraîner des incohérences dans les données et, en fin de compte, la perte de celles-ci. RAID5 et RAID6 ne conviennent pas aux systèmes susceptibles de subir des arrêts imprévus, tels qu'une panne de courant ou un verrouillage du noyau. To learn more, read this article.
A noter que mkfs.btrfs peut recevoir plusieurs périphériques comme arguments. Utilisez les clés suivantes pour gérer votre configuration raid : -d pour les données régulières et -m pour les métadonnées. Les valeurs acceptées sont RAID0, RAID1, RAID10, RAID5, RAID6, single et dup. -m single signifie qu'il n'y a pas de duplication. Ceci est nécessaire si on utilise un raid matériel.
Balance
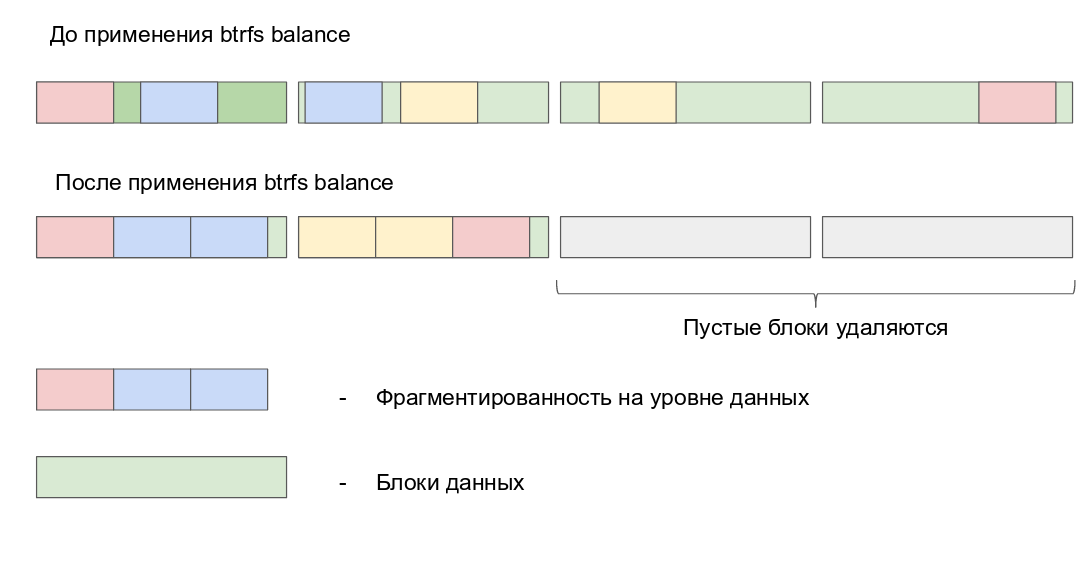
L'objectif principal de la fonction Balance est de répartir les groupes de blocs entre tous les périphériques, de manière à ce qu'ils respectent les restrictions définies dans leurs profils respectifs. Balance ne peut fonctionner que sur un système de fichiers monté. La portée de Balance peut encore être ajustée à l'aide de filtres, qui visent à traiter des groupes de blocs de manière sélective.
Contrairement à la plupart des systèmes de fichiers courants, Btrfs utilise une allocation en deux temps. Dans un premier temps, de grandes zones d'espace communément appelées chunks sont allouées à certains types de données. Ensuite, lors de la deuxième étape, des blocs (blocs) sont alloués. Il existe trois types de blocs :
- Les chunks de données contiennent les données communes du fichier.
- Les chunks metadata gardent la trace des métadonnées liées aux fichiers, y compris les horodatages, les sommes de contrôle, les noms de fichiers, les propriétaires, les droits d'accès et les attributs étendus.
- Les chunks système sont un type spécial de chunks qui stockent des données dans l'emplacement de tous les autres chunks.
Le seul type de données pouvant être stocké dans un bloc est celui auquel le bloc est affecté. Actuellement, la situation la plus courante dans laquelle vous obtenez une erreur ENOSPC dans Btrfs est lorsque le système de fichiers n'a plus d'espace pour les données ou les métadonnées dans les chunks existants et qu'il ne peut pas allouer un nouveau chunk. Vous pouvez vérifier que c'est bien le cas en exécutant btrfs fi df <chemin> sur le système de fichiers qui a déclenché l'erreur. Si la ligne " Data " ou " Metadata " affiche une valeur "Total", complètement différente de la valeur "Used", c'est probablement pour cette raison.
btrfs balance renvoie les données sur l'allocateur, ce qui permet une optimisation de l'espace. Par exemple, si deux blocs de métadonnées sont remplis à 40 %, Balance les fusionnera en un seul bloc de métadonnées rempli à 80 %. Maintenant, Balance peut supprimer les blocs vides et faire de la place pour de nouveaux blocs, qui pourront à leur tour être attribués aux chunks pertinents. Si vous exécutez btrfs fi df <chemin> après avoir démarré Balance, les valeurs Total et Ued deviendront beaucoup plus proches l'une de l'autre, car cette commande supprime les fragments qui ne sont plus nécessaires.
Important
Vous devez créer un nouveau groupe de blocs provisoire pour btrfs balance et y déplacer les anciennes données. Cela demande de la mémoire disponible, sinon vous aurez une erreur de ENOSPC. Ce problème peut être résolu en connectant temporairement un disque supplémentaire.
Scrub
btrfs scrub start <chemin_d_accès> lit tous les blocs de données et les métadonnées de tous les périphériques et vérifie les checksums. Les blocs endommagés seront restaurés automatiquement s'en existent une copie correcte.
Note
Scrub n'a pas été conçu pour inspecter les systèmes de fichiers (à l'image de fsck) et ne vérifie ni ne répare les dommages structurels.
Les utilisateurs ont le choix entre la commande manuelle et cron. Le rythme mensuel est recommandé, mais cela peut aussi être à des intervalles plus rapprochés.
En fonction des paramètres de votre disque, btrfs scrub réparera les données endommagées en copiant une version intacte à partir d'un autre support de stockage, lors de la configuration d'un RAID1. S'il n'y a qu'une seule copie des données ou si toutes les copies sont corrompues, btrfs scrub va produire un message de données corrompues. S'il n'y a pas d'erreur, 0 sera renvoyé.
Défragmentation
À partir du premier enregistrement de données, Btrfs procède de manière séquentielle, mais COW (Copy-On-Write) implique qu'aucune modification ultérieure du fichier ne peut se superposer à d'anciennes données et doit donc être stockée dans un bloc vide. Cela entraîne une fragmentation importante du système de fichiers. En outre, les CoW rencontrent aussi des problèmes de fragmentation inhérents à tous les systèmes de fichiers.
Btrfs prévoit plusieurs méthodes pour contrôler la fragmentation :
- défragmentation en exécutant
btrfs filesystem defragment <path>
Important
Le système Copy-on-Write enregistre les données dans un nouvel emplacement à chaque mise à jour, les rendant au passage plus fragmentées. La défragmentation casse également les liens renvoyant aux données COW, telles que les fichiers copiés avec `cp --reflink', les instantanés ou encore les données dédoublées. Cela peut permettre une augmentation significative de l'espace disque utilisé.
- option de montage -o nodatacow , qui désactive COW pour les données régulières. La défragmentation peut être utilisée sur un fichier autonome ou sur un sous-volume/répertoire, y compris de manière récursive. L'attribut nocow peut également être défini pour un nouveau fichier ou un fichier vide. Il désactive la fonction copy on write, de sorte que Btrfs travaille toujours avec une zone de disque fixe lorsqu'il met à jour le contenu d'un fichier, en enregistrant les données dans une zone (physiquement) existante.
Important
L'activation de l'attribut nocow désactive les sommes de contrôle.
- option de montage -o autodefrag . Elle détecte les petites entrées aléatoires dans les fichiers et les met en file d'attente pour une défragmentation automatique, de sorte que le système de fichiers se défragmente de lui-même lorsqu'il est utilisé. Cette option n'est pas adaptée à la virtualisation ou aux bases de données très chargées, mais convient bien aux petits fichiers tels que les bases de données rpms, SQLite ou bdb.
Note
Pour évaluer la fragmentation estimée de votre système, vous disposez de l'outil filefrag.
Trim
Btrfs peut informer le SSD que les blocs de données ne sont plus utilisés (fichiers distants, etc.), évitant ainsi une diminution progressive des performances du SSD. C'est bien à cela que sert fstrim. Disponible pour la plupart des disques SSD récents.
Btrfs détecte automatiquement les disques SSD au moment du montage, mais fstrim doit être exécuté manuellement ou activé via l'option -o discard, pour le lancer chaque fois qu'un fichier est supprimé.
Il est à noter qu'une utilisation excessive de fstrim et même de -o discard peut compromettre la durée de vie des périphériques SSD bas de gamme. Pour en savoir plus sur ce problème, consultez [cet article] (http://asalor.blogspot.com/2011/08/trim-dm-crypt-problems.html). En outre, la méthode CoW utilisée sur Btrfs réduit le nombre d'écrasements. TRIM est donc largement superflu pour Btrfs.