Btrfs
Updated 7 April 2021
![]()
Introduction
Btrfs is a file system intended to address the growing scalability requirements of large storage subsystems. Its name is derived from the B-tree data structures used by Btrfs. The B-tree is a tree data structure that allows filesystems and databases to efficiently access and update large blocks of data, whatever the size of the tree.
At partitioning time, you can select Btrfs as the filesystem when installing Calculate Linux. The installer will then format accordingly the partition you selected. In addition, you can use `mkfs.btrfs' to create a Btrfs file system on one or more block devices. The default is to partition the data and mirror the file system metadata. When you specify a single device, the metadata is duplicated on that device unless you have specifically said that only one copy of the metadata should be used. Devices can be plain disk partitions, loopback devices (i.e. disk images stored in memory), multipath devices or LUN devices that implement RAID at the hardware level.
Functionality
Here are the main Btrfs' features:
- Copy-on-write allows you to create both readable and writable snapshots, as well as restore your filesystem, even after an ext3 or ext4 conversion. Use the following command to create a snapshot:
btrfs subvolume snapshot <source> <[dest/]name>To prevent modifications, add the -r key. - The checksum ensures data integrity.
- Integrated compression saves disk space. Compression can be enabled by option compress=zlib or compress=lzo when mounting the storage volume. Compression can also be enabled for files individually without using the mount option: to do this, please apply
chattr +c <[dest/]name>to the file. When this is applied to directories, new files will be automatically compressed as they are submitted. - Integrated defragmentation improves productivity.
- Integrated logical volume management enables RAID configurations to be implemented, as well as the dynamic addition and removal of storage capacities.
Btrfs supports RAID0, RAID1, RAID10, RAID5 and RAID6. It can also duplicate metadata or regular data on a single drive or multiple drives.
Warning
RAID5 and RAID6 are known to currently have issues with data integrity and should not be used for metadata storage. The problem is, fragmented writing caused biy a power failure would result in data inconsistency, and ultimately to data loss. RAID5 and RAID6 are not suitable for systems that may experience unplanned shutdowns ( such as power failure or kernel lockdown). To learn more, read this article.
Note that mkfs.btrfs may take multiple devices as arguments. Use the following keys to manage your raid configuration: -d for regular data and -m for metadata. The accepted values are RAID0, RAID1, RAID10, RAID5, RAID6, single, and dup. -m single means that there is no duplication. This is necessary when using a hardware raid.
Balance
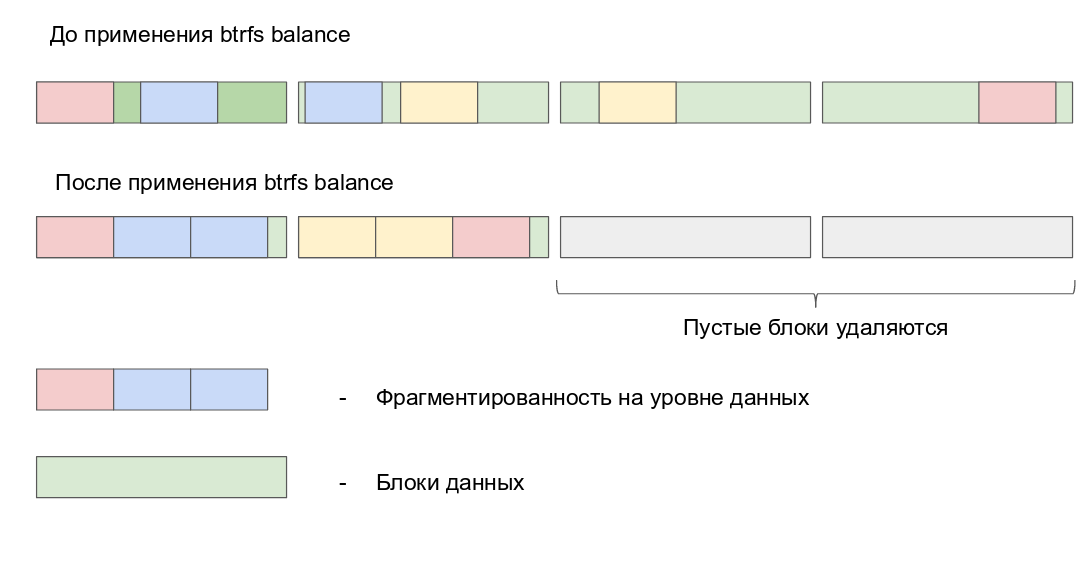
The main purpose of the Balance function is to distribute groups of blocks across all devices, so that they meet the restrictions defined in the respective profiles. Balance can operate only on a mounted file system. The scope of balancing can be further adjusted with filters, that process groups of blocks selectively.
Unlike most common file systems, Btrfs uses a two-step allocator. At the first stage, large space areas commonly referred to as chunks are allocated for certain data types. Then at the second stage, blocks (blocks) are allocated. There are three types of chunks:
- Data chunks store common file data.
- Metadata Chunks keep track of metadata related to files, including time stamps, checksums, file names, owners, permissions, and extended attributes.
- System Chunks are a special type of chunks that store data about where all other chunks are located.
The only data type that can be stored in a block is the one that the block is allocated to. Currently, the most common situation when you get a ENOSPC error in Btrfs is when the file system has run out of space for data or metadata in existing chunks and cannot allocate a new chunk. You can check that this is the case by running btrfs fi df <path> on the file system that triggered the error. If the "Data" or "Metadata" line displays a "Total" value that is significantly different from the "Used" value, this is probably why.
btrfs balance sends the data back over the allocator, resulting in a more space-efficient use of chunks. For example, if you have two metadata blocks that are 40% full, Balance will merge them into one metadata block that is 80% full. Balance can now remove the empty blocks, making room for new ones, which can in their turn then be assigned to applicable chunks. If you run btrfs fi df <path> after launching Balance, the Total and Ued values will become much closer to each other, as it removes fragments that are no longer needed.
Important
Note that you need to temporarily create a new group of blocks for btrfs balance and move the old data there. This requires free memory, otherwise you will get a ENOSPC error. You can solve this problem by temporarily connecting an additional drive.
Scrub
btrfs scrub start <path> reads all data blocks and metadata from all devices and checksums. It automatically restores damaged blocks if they have a good copy.
Note
Scrub was not designed to check filesystems (such as fsck) and does not check or repair structural damage.
Users must run it manually or use cron. The recommended period is a month, but it may be less.
Depending on your disk settings, btrfs scrub will repair the damaged data by copying an undamaged version from another storage medium when setting up RAID1. If there is only one copy of the data or all copies are corrupted, btrfs scrub will generate a corrupted data message. If there are no errors, it will return 0.
Defragmentation
As of the first record, Btrfs writes data sequentially, but the COW Copy-On-Write) implies that any subsequent file modification must not be written on top of old data, and must therefore be stored in a vacant block. This causes high fragmentation of the filesystem. Besides, COW file systems also encounter fragmentation problems inherent to all file systems.
Btrfs provides several methods to control fragmentation:
- defragmentation by running
btrfs filesystem defragment <path>
Important
The Copy-on-Write system writes data to a new location at every update time, thus making it more fragmented. Defragmentation will also break links to COW data (e.g. files copied using `cp --reflink', snapshots or deduplicated data). This may result in a significant increase in the amount of disk space used.
- mount option -o nodatacow , which disables COW for regular data. Defragmentation can be used on a standalone file or on a subvolume/directory, including recursively. The nocow attribute can also be set for a new or an empty file. It disables the copy on write function, so that Btrfs would always work with a fixed disk area when it updates file contents, writing data over existing one (at the physical level).
Important
Enabling attribute nocow - disables checksums.
- mounting option -o autodefrag . It detects small random entries in files and queues them for automatic defragmentation, so the file system would defragment itself while it is in use. This option is not suitable for virtualization or highly loaded databases, but is well suited for small files such as rpms, SQLite or bdb databases.
Note
You can use the filefrag tool to get an estimate of file fragmentation on your system.
Trim
Btrfs can inform the SSD which data blocks are no longer in use (remote files, etc.), thus avoiding, at least, a progressive decrease in the SSD performance. That is what fstrim was designed for. It is available for most of the latest SSD drives.
Btrfs automatically detects SSDs at mount time, but fstrim needs to be run manually or enable via the -o discard option, which will run the fstrim tool every time a file is deleted.
Note that excessive fstriming or even using -o discard can compromise the lifetime of low-cost SSD devices. To learn more about this problem, check this article. In addition, the CoW method as used on Btrfs reduces the number of overwrites, so TRIM is not really necessary for Btrfs.